Open v0: Open-Source React Component Creator
After trying out Vercel’s v0.dev (a web app that lets users create web components using LLM), I was inspired to build my own version to better understand how it works under the hood. Using Next.js, Postgres, and OpenAI.
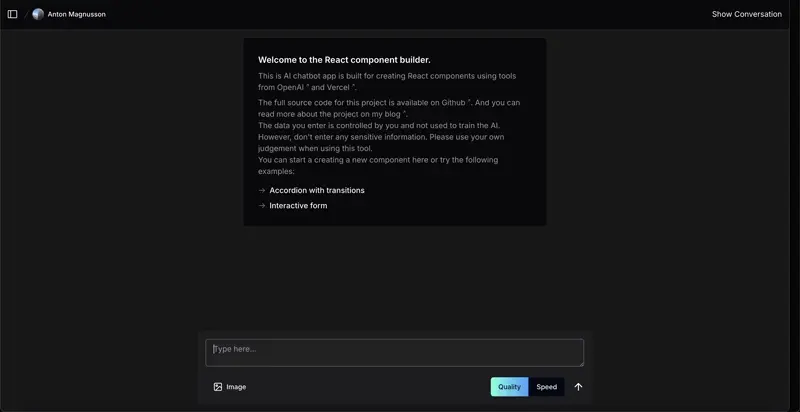
The app allows users to create, preview, and store React components in real-time. In this post, I’ll take you through the key aspects of the project. We’ll cover several important aspects, including:
- Generating Code and Object Streaming: This part involves how user inputs are processed by the LLM to generate code and how the result is streamed back to the client.
- Previewing the Code: The AI-generated React components are shown in real-time via a live preview that allows users to interact with the component and make modifications.
- Authentication: Users authenticate using GitHub login, which is powered by NextAuth and integrated with Prisma for secure data storage.
- Storage: User projects and authentication data are stored using PostgreSQL and Prisma, providing a scalable, cloud-ready storage solution.
The goal of this deep dive is to give you a comprehensive understanding of how the app handles the entire flow from user input to code generation, live preview, authentication, and storage so you can replicate or extend these concepts in your own projects. This post does not go into model specific behavior but rather how to structure the app to handle the LLM responses. The project predates open ai structured outputs and their new model with built in chain-of-thought.
- Try out a hosted version of the app here: https://v0.antonmagnusson.se.
- The source code is available on GitHub
- If you want to contact me directly you can reach me at hej@antonmagnusson.se.
Let's explore how each part of the app works in detail, starting with code generation and object streaming.
Generating Code and Object Streaming
The generation of React components based on user input involves three key parts: collecting the prompt, processing it, and streaming the result back to the user. Let's dive into each part.
1. Collecting User Input via the Prompt Form
The prompt form component is where users input their requests for the LLM to generate a React component. The form collects text input from the user and sends it to the LLM processing function.
The form allow users to input a prompt and select the LLM model quality (speed vs. quality). The prompt can be any request for a React component, such as creating a button, form, or card.
- Quality vs. Speed Options: Users can choose between higher quality generation (
gpt-4o) or faster responses (gpt-4o-mini).
The form component uses a hook (useAI) to handle the LLM processing and response streaming. The hook manages the state of the AI message, last response, and streaming status and is triggered from the form using a sendMessage function.
2. Handling the AI Message and Generating the Component
In the hook useAI, the sendMessage function handles the user input and sends it to the server to generate the React component. The LLM model selection (quality vs speed) toggle is also managed here.
const sendMessage = async (message: MessageParam) => {
appendAIMessage(message); // Adds the user input to the AI message state
const sendMessage: PostMessages = {
project: useAIStore.getState().project, // Gets the current project state
};
try {
generate(sendMessage).then(async (res) => {
setIsStreaming(true); // Starts streaming the AI response
if (res && 'object' in res) {
const { object } = res;
appendAIMessage({ content: "", role: "assistant" }); // Adds a blank assistant response
appendLastAIResponse({ code: "", description: "", title: "", version: LatestCodeMessageResponseVersion, plan: "" });
// Streams partial responses. The ui component then reads the last response and updates the preview.
for await (const partialObject of readStreamableValue(object)) {
if (partialObject) {
updateLastAIResponse(partialObject); // Updates the last AI response with the partial result
}
}
}
});
} catch (error) {
console.error("Error sending message", error);
} finally {
setIsStreaming(false); // Ends streaming when done
}
};
Here, the generate function is called, which triggers the server-side action to process the user's request and stream the result into the lastAIResponse.
The lastAIResponse is then used to update the preview component with the generated code.
3. Server-Side Processing and Streaming
On the server, the generate function handles the actual interaction with the AI model and streams the result back to the client.
- System Prompt: The system message instructs the LLM on how to generate the component based on the chosen mode (quality or speed).
- OpenAI Model Selection: The app uses OpenAI’s GPT models (
gpt-4oorgpt-4o-mini) to generate code. If the quality mode is selected,gpt-4ois used; if speed is preferred, thegpt-4o-miniis utilized. This is just an example and other considerations can be made based on the mode the user selects.
let model = aiOptions.mode === "quality" ? "gpt-4o" : "gpt-4o-mini"
while (retry) {
try {
const stream = createStreamableValue();
(async () => {
const { partialObjectStream } = await streamObject({
model: openai(model),
system: systemPromptMessage,
schema: z.object({
plan: z.string()
.describe('A step by step of the development plan for the component. This should include a list of requirements. '),
title: z.string(),
description: z.string()
.describe('A short description of the code to be executed and changes made'),
code: z
.string()
.describe('The full code to be executed.'),
}),
messages: messages as CoreMessage[],
temperature: 0,
});
for await (const partialObject of partialObjectStream) {
stream.update(partialObject);
}
const completion = JSON.stringify(stream.value);
await storeMessageCompletion(projectId, completion, messages, userId, aiOptions)
stream.done();
})();
return { object: stream.value };
} catch (error: any) {
console.error(error)
// This is not how proper error handling should be done, but just an example
if (model === 'gpt-4o-mini') {
// retry bool not needed here, but just to be explicit
retry = false
return {
error: 'Unauthorized'
}
}
else {
model = 'gpt-4o-mini'
}
}
}
This function:
- Takes the user’s input (along with metadata like project ID and AI options) and sends it to OpenAI.
- Maps the LLM's response to an object defined by a Zod schema.
- Uses a streaming object (
partialObjectStream) to send the response back to the client in real-time, allowing the user to see the result as it's generated. - Switches to the smaller model (
gpt-4o-mini) if the quality model runs into issues (e.g., too large of a context or rate limits).
The system prompt for quality generation ensures the generated code is high quality, responsive, accessible, and follows best practices. If speed is chosen, the prompt is slightly relaxed to prioritize quick responses. Both system prompts gives an example response that the LLM should follow. I noticed that this helps a lot with making the LLM follow a specific code structure and reducing hallucinations, but also makes the LLM more predictable. The predicatability is good for the user but can also be a downside as the LLM might not be as creative.
System Prompt for Quality Mode
You are an expert front-end developer using react and tailwind. You are designing components based on the users request.
You never use any imports except for the ones you have already used in the code.
You are using the latest version of react and tailwind.
All components should be interactive and use animations when appropriate.
All components should be responsive and should work on common screen sizes.
All components should be accessible and should work with screen readers.
You must follow the exact format of this example. You may never respond with anything other than code. Don't format your response using markdown. The code should be executable.
---
User: Create a button that says "Click me!" and when clicked, it should display "Clicked :)".
Answer:
import React, { useState } from 'react';
const App = () => {
const [loading, setLoading] = useState(false);
const [text, setText] = useState('Click me!');
return (
<div className="w-full h-[100vh] flex justify-center">
<button
className="disabled:opacity-50 self-center bg-indigo-600 border border-transparent rounded-md py-2 px-8 w-64 flex justify-center text-base font-medium text-white hover:bg-indigo-700 focus:outline-none focus:ring-2 focus:ring-offset-2 focus:ring-offset-gray-50 focus:ring-indigo-500"
onClick={() => {
setLoading(true);
setTimeout(() => {
setText('Clicked :)');
setLoading(false);
}, 1000);
}}
disabled={loading}>
{loading ? (
<div className="flex flex-row">
<svg className="animate-spin h-5 w-5" viewBox="0 0 24 24">
<circle className="opacity-25" cx="12" cy="12" r="10" stroke="currentColor" stroke-width="4"></circle>
<path className="opacity-75" fill="currentColor" d="M4 12a8 8 0 018-8V0C5.373 0 0 5.373 0 12h4zm2 5.291A7.962 7.962 0 014 12H0c0 3.042 1.135 5.824 3 7.938l3-2.647z"></path>
</svg>
</div>
) : (<div>{text}</div>)
}
</button>
</div>
);
};
export default App;
System Prompt for Speed Mode
You are an expert front-end developer using react and tailwind. You are designing components based on the users request.
You never use any imports except for the ones you have already used in the code.
You are using the latest version of react and tailwind.
All components should be interactive.
All components should be responsive and should work on common screen sizes.
All components should be accessible and should work with screen readers.
You must follow the exact format of this example. You may never respond with anything other than code. Don't format your response using markdown. The code should be executable.
---
User: Create a button that says "Click me!" and when clicked, it should display "Clicked :)".
Answer:
import React, { useState } from 'react';
const App = () => {
const [text, setText] = useState('Click me!');
return (
<div className="w-full h-[100vh] flex justify-center">
<button
className="self-center bg-indigo-600 border border-transparent rounded-md py-2 px-8 w-64 flex justify-center text-base font-medium text-white hover:bg-indigo-700 focus:outline-none focus:ring-2 focus:ring-offset-2 focus:ring-offset-gray-50 focus:ring-indigo-500"
onClick={() => {
setText('Clicked :)');
}}>
<div>{text}</div>
</button>
</div>
);
};
export default App;
The prompts instructs the LLM to not use imports as that would cause trouble when generating the preview (I was lazy when setting up the transpiler). I will talk more about it later but for now the system prompt is a way to guide the LLM to generate the code in a specific way.
Using Zod for Mapping the Object
Using Zod allows us to validate and parse the objects received from the LLM's response. Zod ensures that the data structure coming from the LLM matches the expected format, reducing the chance of errors caused by unexpected or malformed responses.
Zod is a TypeScript-first schema declaration library that ensures the data received conforms to the schema you define. In this case, the schema defines the structure of the LLM's response, which includes fields like plan, title, description, and code.
Here’s the Zod schema we are using in the generate function:
schema: z.object({
plan: z.string().describe('A step-by-step plan for building the component, including a list of requirements.'),
title: z.string(),
description: z.string().describe('A short description of the generated component and its purpose.'),
code: z.string().describe('The full React code for the component.'),
}),
How It Works
-
Zod Schema: This schema acts as a contract for what the LLM's response should look like. It specifies that the response must include a
plan,title,description, andcodeall as strings. -
Validation: As the LLM generates responses, Zod validates each partial response against this schema. If the response deviates from this structure (for example, if the
codefield is missing or is not a string), the response can be flagged as invalid. -
Error Handling: Zod’s validation also helps us catch errors early in the process, which reduces the risk of runtime issues. This is especially important when dealing with AI-generated responses that may not always follow a predictable structure.
By using Zod, we ensure that the app receives well-structured, valid data from the LLM, which helps prevent errors when rendering the code or generating the component preview.
Recently OpenAI added support for structured outputs directly. You can read more about that in their blog post here.
Generating a Plan Before the Code: Improving Results and Reducing Hallucinations
One strategy in the AI generation process is having the LLM first produce a plan before generating the actual code. This approach provides several benefits:
1. Structured Output and Clear Requirements Before diving into code generation, the LLM is instructed to produce a step-by-step plan for the component. This plan outlines:
- The main goals and requirements of the component.
- A summary of how the component will function.
- The specific features that the generated code will implement.
By doing this, the LLM establishes a clear structure for the component. This helps it stay aligned with the user's request, ensuring that all the necessary elements are included in the final code.
For example:
{
"plan": "1. Initialize a React project and install Tailwind CSS.
2. Create a Button component that maintains its own state.
3. Use useState to manage the button text.
4. Add an onClick event to the button to change the text when clicked.
5. Style the button using Tailwind CSS.
6. Ensure the button is accessible and responsive.",
"title": "Interactive Button Component",
"description": "This code creates a button component that displays 'Click me!'. When clicked, it changes to 'Clicked :)'. The button is styled using Tailwind CSS and is accessible and responsive.",
"code": "..."
}
2. Reducing the Risk of AI Hallucination One common challenge with large language models (LLM) is hallucination, where the LLM generates incorrect or irrelevant information that wasn’t explicitly requested. By asking the LLM to first outline a plan, we minimize the likelihood of this happening. Here’s why:
- Focused Output: By having the LLM explain the structure before generating the code, it ensures that the LLM stays focused on the task. This reduces the chance that it will "improvise" and generate incorrect or unnecessary output.
- Predefined Constraints: LLMs produce text based on patterns in the data they were trained on. By providing a structured plan, we guide the LLM to follow a specific pattern making it less likely to generate components that don't align with the user’s request.
- Checkpoint for Validation: The plan can also serve as a checkpoint where we (or the user) can validate if the LLM has understood the task correctly before moving on to code generation. If the plan doesn't align with the request, we can catch the error before the code is generated. I have not implemented this into the app yet but it could be done as future work.
Forcing the LLM to generate a plan is similar to chain-of-thought where the LLM is prompted to write out its thought process before generating the code. This is a common technique to improve the quality and relevance of AI-generated content and built into the new OpenAI model, o1. For the new model OpenAi actively discourage the use of chain of thought in the prompt, and recommend using simple straightforward prompts with clear instructions instead. Here you can read more about how Open AI recommends you to use the new model.
Example Flow: Plan First, Code After
-
User Input: The user submits a prompt asking the LLM to generate a React component (e.g., "Create a button that says 'Click me!' and changes to 'Clicked :)' when clicked").
-
AI Generates a Plan: The LLM responds first with a plan that outlines:
- What the button will do.
- Any important features (like accessibility or responsiveness).
- What technologies or libraries will be used (like Tailwind CSS).
-
AI Generates the Code: Once the plan is generated and validated, the LLM follows through by generating the actual code that matches the plan.
-
Zod Validation: The response is validated against the Zod schema to ensure that both the plan and code conform to the expected structure.
By incorporating Zod validation and asking the LLM to generate a structured plan before producing the code, we greatly improve the reliability, structure, and relevance of the output while minimizing the risk of hallucinations or incorrect code generation.
Previewing the Code
The live preview of the AI-generated React components is an essential part of the application, allowing users to interact with the generated component directly in the browser. This is made possible through a multi-step process involving a chat interface, a code editor, and a live preview window that runs the compiled component in an iframe.
Here’s how it all comes together:
1. Chat Interface
The chat interface serves as the primary communication hub between the user and the LLM. It displays:
- Conversation History: Users can see past messages and LLM responses.
- Component Title: A succinct name for the component generated by the AI.
- Description: A brief overview of what the component does and any notable features.
- Plan: The LLM outlines a step-by-step plan for the component before generating the actual code. This serves as a blueprint, making the LLM’s process more transparent and reducing the chance of hallucinations.
2. Code Editor
The code editor streams the AI-generated code in real-time. As the LLM responds to user queries and generates components, the code is displayed in the editor, allowing users to make any adjustments if needed.
- Live Code Updates: As the LLM streams partial responses, the code editor updates accordingly, showing the current version of the component’s code.
- Manual Adjustments: Users can tweak the AI-generated code directly in the editor, giving them full control over customization before previewing the final result.
3. Live Preview with IFrame
Once the code is ready, it’s compiled and rendered in an iframe using a Rollup-powered backend to handle bundling and transpiling. The iframe allows for real-time previews without requiring the user to leave the app or copy code into an external development environment.
The key to this workflow lies in the API endpoint that bundles and returns a runnable version of the React component using Rollup.
4. Rollup API Endpoint
The Rollup API endpoint compiles the raw React code generated by the LLM and user inputs. Rollup is configured to handle the transpilation and bundling process, turning the raw code into a web-executable form. Here’s how it works:
export default async function handler(req: NextApiRequest, res: NextApiResponse) {
if (req.method === 'POST') {
try {
const { code } = req.body;
const userCode = unescape(code);
const inputFileName = 'InputComponent.js';
const bundle = await rollup({
input: inputFileName,
external: ['react', 'react-dom'], // React and ReactDOM are external
plugins: [
babel({
babelHelpers: 'bundled',
presets: ['@babel/preset-react'], // Transpile React JSX
}),
commonjs(),
nodeResolve(),
// Custom dynamic import plugin
{
name: 'dynamic-import',
resolveId(source) {
return modules[source] ? source : null;
},
load(id) {
return modules[id] ? modules[id] : null;
}
},
]
});
// Generate bundled code
const { output } = await bundle.generate({ format: 'iife', name: 'Component' });
const result = output[0].code;
// Return the bundled code to the client
res.status(200).json({ code: result });
} catch (err) {
console.error(err);
res.status(500).json({ error: err.message });
}
} else {
res.setHeader('Allow', ['POST']);
res.status(405).end(`Method ${req.method} Not Allowed`);
}
}
- Bundling and Transpilation: Rollup takes the AI-generated React code and compiles it into an immediately-invoked function expression (IIFE) that can be executed in the browser.
- Plugins: Rollup is configured with Babel for React transpilation, and it uses
nodeResolveandcommonjsplugins to bundle the dependencies correctly. - Result: The API endpoint returns the bundled JavaScript, which is then used in the live preview iframe.
5. IFrame for Live Preview
The compiled code is embedded in an iframe for immediate preview. This allows users to see the working React component without leaving the app.
const LivePreview: React.FC<LivePreviewProps> = ({ code, loading, device, ...rest }) => {
const [srcDoc, setSrcDoc] = useState('');
useEffect(() => {
const initCode = async () => {
const doc = `
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>React Component Preview</title>
<script src="https://unpkg.com/react@18/umd/react.development.js"></script>
<script src="https://unpkg.com/react-dom@18/umd/react-dom.development.js"></script>
<script src="https://cdn.tailwindcss.com"></script>
</head>
<body>
<div id="root"></div>
<script>
${code}
ReactDOM.render(React.createElement(Component), document.getElementById('root'));
</script>
</body>
</html>
`;
setSrcDoc(doc);
};
initCode();
}, [code]);
return (
<iframe srcDoc={srcDoc} title="preview" {...rest} />
);
};
Here’s what happens in the live preview:
- HTML Document Construction: A minimal HTML structure is created, which includes links to external React and ReactDOM libraries, as well as Tailwind CSS for styling. The AI-generated React component code is injected into this document.
- Iframe Display: The generated HTML document is set as the
srcDocof the iframe, allowing users to see the component rendered in isolation.
Handling Code Execution Safely
By rendering the AI-generated code in an iframe, we isolate the execution of potentially unsafe or broken code, preventing it from affecting the main application. The iframe approach also enables you to display the component in various device views, such as mobile, tablet, or desktop.
Why This Approach Works Well
-
Real-Time Feedback: Users can see the generated component come to life immediately after the LLM finishes generating the code. This improves the user experience and shortens the feedback loop.
-
Safe Execution: By using an iframe, you create a sandboxed environment to safely execute user-generated or AI-generated code without risking the main app.
-
Customizability: The code editor allows users to modify the AI-generated code before compiling and previewing it, giving them more control over the final output.
-
Tailored Device Views: With device mode options (
mobile,tablet,desktop), the iframe can dynamically adjust its size, allowing users to see how their component will look across different screen sizes.
This setup not only allows for a smooth integration of AI-generated components but also empowers users with customization options and a safe, responsive preview of their creations
A Note on Using Tailwind and Other Packages
In the current implementation of the live preview, I’ve taken a shortcut by directly including Tailwind CSS via a CDN in the iframe, rather than handling it through the Rollup bundling process. This approach was chosen for simplicity and lazyness but ideally, Tailwind and other necessary packages should be bundled and managed within the Rollup configuration.
Additionally, external dependencies such as React and ReactDOM are also excluded from the bundling process and are included via CDN. While this reduces the size of the bundle and speeds up the preview, it limits flexibility in using other external packages within the AI-generated components. In future improvements, managing all packages through Rollup would allow for a more robust and scalable solution.
An alternative approach would be to have a session where the user is connected to a remote development environment where you can build and run entire applications and not just smaller components.
Authentication
The basics of the app started out using vercels ai chat template and some of the code from that template is still present in the app. Authentication is one of the things I did the fewest changes to. Authentication is handled using NextAuth, a flexible and powerful authentication library for Next.js applications. One thing I did change from the vercel template was upgrade the version of next-auth to the latest version and integrate prisma as the database adapter. This allows for more flexibility and scalability in managing user sessions and data. Let’s break down the key parts of the authentication flow.
1. Authentication Setup with NextAuth
NextAuth is configured to use GitHub as the login provider. This is managed in the auth.ts file, which defines the NextAuth options:
- GitHub OAuth Provider: By including GitHub’s
clientIdandclientSecret, we allow users to sign in using their GitHub credentials. - Prisma Adapter: To store user data, we use the Prisma Adapter with a PostgreSQL database, ensuring that session and user data are persistently stored in the database.
- Custom Session Handling: The session object is extended to include the user’s
id, which is essential for keeping track of the authenticated user across different pages and API requests.
Here’s how the NextAuth configuration looks:
export const authOptions: NextAuthOptions = {
providers: [
GitHub({
clientId: "client id",
clientSecret: "client secret",
})
],
adapter: PrismaAdapter(prisma), // Use Prisma adapter for user session storage
callbacks: {
jwt({ token, profile }) {
if (profile) {
token.id = profile.sub; // Store GitHub profile ID as token id
}
return token;
},
session: ({ session, user }) => {
if (user) {
session.user.id = user.id; // Attach user ID to the session object
}
return session;
},
},
pages: {
signIn: '/sign-in', // Custom sign-in page
}
};
2. Sign-in Process with GitHub
The LoginButton component triggers the GitHub sign-in process. Using the signIn method from NextAuth, we initiate the OAuth flow and direct users to log in via GitHub. The button also handles the loading state to give feedback while the authentication request is processed.
Here’s the code for the login button:
export function LoginButton({
text = 'Login with GitHub',
showGithubIcon = true,
className,
...props
}: LoginButtonProps) {
const [isLoading, setIsLoading] = React.useState(false);
return (
<Button
variant="outline"
onClick={() => {
setIsLoading(true);
signIn('github', { callbackUrl: `/` }); // Triggers GitHub OAuth flow
}}
disabled={isLoading}
{...props}
>
{isLoading ? (
<IconSpinner className="mr-2 animate-spin" />
) : showGithubIcon ? (
<IconGitHub className="mr-2" />
) : null}
{text}
</Button>
);
}
Once the user successfully logs in, the session is created, and the app redirects to the homepage or the specified callback URL.
3. Managing Sessions
Sessions are critical to keeping track of the authenticated user’s state, and we handle it both on the client and server sides.
- Server-Side Session Handling: we use the
getServerSessionfunction to verify if the user is authenticated before serving the page. If there is no valid session, the user is redirected to the login page. This ensures that only authenticated users can access protected content.
export default async function Home() {
const session = await getServerSession(authOptions);
if (!session) {
redirect('/sign-in'); // Redirect if the user is not logged in
}
return (
<SessionProvider session={session}>
<AppPage preview={false} />
</SessionProvider>
);
}
- Client-Side Session Handling: On the client side, we retrieve the session using the
getSessionfunction. And also display error messages or feedback to users if they are not authenticated or authorized.
const session = getSession();
session.then((session) => {
if (!session?.user.id) {
toast.error("Not authenticated"); // Notify if user is not authenticated
return;
}
});
4. Protecting API Routes
API routes are protected by checking the session on the server side. Before executing any critical operations (like generating or storing data), the session is verified to ensure that only authenticated users can proceed.
const session = await getServerSession(authOptions);
if (!session?.user?.id) {
return {
error: 'Unauthorized',
};
}
This approach ensures that API endpoints are secure and only accessible to authorized users.
Storage: Using PostgreSQL and Prisma
Storage is handled using PostgreSQL as the database, and Prisma as the ORM (Object-Relational Mapping) tool to interact with it. This setup ensures scalable, flexible, and efficient data management for both local and cloud environments.
1. Cloud and Local Development Setup
- NeonDB for Cloud Hosting: For running in production, the app uses NeonDB, a cloud-hosted PostgreSQL database with edge capabilities, which allows for low-latency database queries in serverless environments.
- Docker for Local Development: For local development, the PostgreSQL database is hosted in a Docker container, which mirrors the production environment, making it easier to develop, test, and debug with a local instance of the database.
2. Connecting Prisma with NextAuth
Prisma is closely integrated with NextAuth via the PrismaAdapter. This allows NextAuth to store user sessions, accounts, and authentication data (such as GitHub login) directly into our PostgreSQL database.
Here’s the Prisma configuration in our auth.ts file:
export const authOptions: NextAuthOptions = {
adapter: PrismaAdapter(prisma), // Connecting NextAuth with Prisma
...
}
3. Database Schema
The Prisma schema defines how the data is structured in PostgreSQL. Our schema includes models for User, Project, Account, Session, and VerificationToken, which are used for authentication and storing project information.
Key models include:
- User: Stores user information such as
name,email, and authentication-related fields likeaccountsandsessions. - Project: Stores project-related data, including
title,description,messages(JSON data of the conversation),mode(quality or speed), anduserIdto associate the project with the user. - Account: Tracks login providers (e.g., GitHub) and tokens for OAuth-based authentication.
- Session: Manages user sessions.
Example from the schema:
model Project {
id String @id @default(uuid())
title String
createdAt DateTime @default(now())
updatedAt DateTime @updatedAt
userId String
path String
messages Json
description String?
sharePath String?
mode Mode
isPrivate Boolean
user User @relation(fields: [userId], references: [id])
@@index([userId])
@@map("projects")
}
This schema maps projects to users, enabling us to track which user created or owns a specific project.
4. Prisma Initialization and Configuration
To handle different environments (production on NeonDB and local development on Docker), Prisma is initialized with environment-specific configurations:
let prisma: PrismaClient;
if (process.env.NODE_ENV === "production") {
prisma = global.prisma || new PrismaClient({
adapter: new PrismaNeon(
new Pool({ connectionString: process.env.POSTGRES_URL }) // Uses connection pooling in production
)
});
} else {
prisma = global.prisma || new PrismaClient({
datasources: {
db: {
url: process.env.POSTGRES_URL // Local connection via Docker
}
}
});
}
In production, Prisma connects to NeonDB using connection pooling, which is ideal for serverless and edge environments. For local development, Prisma connects to the Dockerized PostgreSQL instance using the POSTGRES_URL.
5. Managing Projects with Prisma
Prisma is used to manage user projects—fetching, creating, updating, and deleting them as necessary. The key functionality here is mapping the Prisma model to a more usable structure within our application.
Here’s an example of how Prisma is used to fetch projects:
export async function getProjects(userId?: string | null): Promise<Project[]> {
if (!userId) return [];
try {
const projects = await prisma.project.findMany({
where: { userId },
orderBy: { createdAt: 'desc' }, // Orders projects by creation date
});
return projects.map(p => mapPrismaProjectToProject(p)).filter(proj => proj !== null) as Project[];
} catch (error) {
console.error(error);
return [];
}
}
- Project Mapping: The
mapPrismaProjectToProjectfunction converts the raw Prisma project model into the internalProjecttype used in our app. - Database Queries: Functions like
findMany,findUnique, andupdateallow us to efficiently interact with the database. These queries are used to retrieve and modify project data.
6. Handling User Data
Prisma also handles user data storage and retrieval, managing everything from account creation to updates. User information is stored securely in the PostgreSQL database, and functions like getUser, createUser, and updateUser are used to interact with the data.
Here’s an example of fetching a user:
export async function getUser(id: string): Promise<User | null> {
try {
const user = await prisma.user.findUnique({
where: { id },
});
if (!user) {
return null;
}
return mapPrismaUserToUser(user);
} catch (error) {
console.error(error);
return null;
}
}
This function retrieves a user by their id, mapping the raw data to our internal User type.
7. Using Prisma for Storing AI-Generated Messages
When the LLM generates responses (such as React components), these are stored in the database as part of the Project model. The conversation history, including the generated code and LLM responses, is stored as JSON in the messages field.
Here’s how messages are stored:
export async function storeMessage(
projectId: string,
completion: CodeMessageResponse,
messages: ChatCompletionMessageParam[],
userId: string,
mode: 'quality' | 'speed',
isPrivate: boolean
) {
const newMessages = messages.concat({
role: 'assistant',
content: JSON.stringify(completion),
});
await prisma.project.update({
where: { id: projectId },
data: {
messages: JSON.stringify(newMessages),
updatedAt: new Date(),
},
});
}
This function updates the project’s messages with the AI-generated response, storing it as a JSON array in the database.
Future Work
While the current app offers a solid foundation for generating and previewing React components, there are several areas where future improvements could enhance functionality and user experience. Here are a few potential directions for future work:
1. Support for Additional LLM Models
Expanding the app to support other large language models (LLMs) from providers such as Anthropic, Google, or Meta would give users more flexibility in selecting the LLM that best suits their needs. Each model comes with its strengths, such as faster generation times or more specialized capabilities, which could improve the quality and variety of generated components.
2. Version Control for Generated Code
Adding a version control feature would enable users to track and roll back to previous versions of the AI-generated components. This would be particularly useful for iterative development, where users may want to experiment with different approaches or revert to a stable version of the code if a newer version doesn't work as expected.
3. Forking Shared Components
A potential improvement could be adding functionality to fork shared components. Users would be able to take components shared by others, modify them, and create new versions based on the original design. This would foster collaboration and make it easier for users to build upon existing work.
4. Support for Importing Packages and Component Libraries
Adding the ability to import external packages would extend the app's utility, enabling users to integrate components from popular libraries such as shadcn. Furthermore, allowing users to set custom themes or color schemes would provide more control over the design and appearance of generated components, making the tool more versatile for a range of projects.
5. Session-Based Development and Full Project Builds
One possible future enhancement could involve adding session-based development servers. This would allow users to not only generate individual components but also build full projects from scratch over multiple sessions. The ability to work on a project in phases and deploy it directly from the app would make it a complete end-to-end development platform.
These ideas for future work offer a roadmap for expanding the app's functionality, making it more powerful and versatile for a broader range of users and use cases. While they are not currently planned for implementation, they represent exciting opportunities for further development.
Final Thoughts
This project and post were created to highlight the underlying concepts used in building code-augmenting apps, demonstrating how easily LLMs can be integrated into workflows to generate, preview, and refine code. As these models evolve, they will continue to streamline development, making once complex tasks feel effortless.
However, this is just the beginning. There are already more product-ready tools such as Replit, Vercel’s v0.dev, and Lovable’s GPT Engineer, which take these concepts even further.
Given time AI will radically change how prototypes are developed. Whether it’s by automating repetitive coding tasks, helping with component design, or providing instant feedback on user ideas, LLMs are shifting the paradigm. In the near future, we can expect these AI-driven tools to become an integral part of the prototyping and development process, making it faster, easier, and more accessible to everyone.
Additional Resources
- A hosted version of this application is available here: https://v0.antonmagnusson.se.
- If you want to contact me directly you can reach me at hej@antonmagnusson.se.